
“Chunks” are groups of words that commonly occur together, and according to research, are likely processed and recorded in the lexicon together. If we can teach language in chunks and encourage students to repeat and remember chunks, we can likely improve their processing efficiency in speaking. Theoretically, they will process language one phrase at a time, rather than one word at a time.
So which chunks do we teach? In a previous post I described a process for finding common chunks that present difficult bottom-up listening challenges for students such as linked and reduced sounds. However, I used a corpus of written English to demonstrate this. If it’s commonly spoken chunks we’re after, we’ll need to look at spoken language data instead. In this post, I aim to show you a few methods for identifying the most common chunks in spoken English so we can get the most “bang for our buck” by teaching them.
Method 1: Analyze your own speech
A good way to determine useful chunks is to simply analyze your own speaking. Which phrases do you find yourself saying often when talking about movies? When talking about work? When ordering coffee, giving your opinion, disagreeing politely? With this approach, I’ve uncovered and taught chunks like the following:
- I read something about…
- I’m afraid there’s gonna be…
- There might be a…
- You mind if I…
If I’m teaching a lesson that involves a debate, I imagine the types of phrases I’d use myself in a debate. If I’m teaching a lesson on food, I think back to conversations I’ve had about food and what I’d find myself saying often. You get the idea!
Method 2: Look at the data
The introspective method above works well for identifying chunks, but I wanted to try a more data-oriented approach. There are useful corpus tools at ngrams.info and phrasesinenglish.org for identifying the most frequent n-grams (groups of n words). Unfortunately neither allows you to filter by only spoken data; most of the data is from written English.
Some good spoken English corpora include The TV Corpus, The Movie Corpus, and Corpus of American Soap Operas, each assembled by linguist Mark Davies. Together they comprise 625 million words. It seems that to search these by n-gram, we need to specify at least one word in the query. In other words, we can’t search for all 4-grams, but we can search for all 4-grams that contain “the” at a certain position, like this: ___ ___ the ___. To do that, we use asterisks like so: * * the *
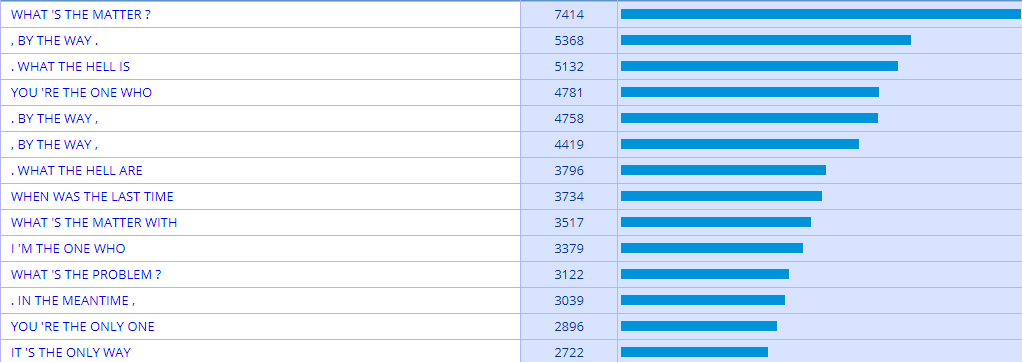
The results show much more colloquial chunks of language than results from my study of n-grams from the iWeb written corpus of English,
I’m still on the hunt for a way to find the most frequent n-grams in spoken English without specifying a word, and will post here once I do. In the meantime, feel free to comment or contact me with any suggestions!

hi
for spoken English you could try the Spoken BNC4, have a look at this post for search terms
https://nextcloud.englishup.me/sites/gplus/multiword-search
ta
mura
Thanks Mura. Great idea! I will definitely look into this. The syntax for finding n-grams is very helpful.